DecisionPackとは
DecisionPack は、顧客CSV、購入履歴、商品、在庫、需要予測、資金シミュレーションを表示するポートフォリオになります。需要予測では、過去の購入や販売の傾向をもとに将来の売れ行きを見積もります。
このポートフォリオは、仕入れ、販売、在庫に関するデータがばらばらに散らばった状態を想定して、これらのデータを整理することで、仕入れ等の判断しやすい形へ整理することを目的にしています。たとえば、顧客データだけを見ても、次に何を仕入れるべきかはすぐには分かりません。在庫だけを見ても、それが売れやすい商品なのか、在庫を持ちすぎている商品なのかは判断が難しいです。しかし、統合して整理することで、画面上で把握しやすくなります。このように、DecisionPack では、顧客、購入履歴、商品、在庫、資金の情報を一つの流れの中で見られるようにすることで、「どの商品を補充すべきか」「在庫が足りなくなりそうか」「仕入れによって資金が苦しくならないか」といった判断を行うために必要な確認材料を揃えています。
DecisionPackはAIが自動で経営判断を下すシステムではなく、最終判断は人が行う前提となっており、人が判断するのに必要な情報を見落としにくくする設計となっています。
画面構成
画面は、顧客、在庫、シミュレーションの3つの確認画面を中心に構成しています。
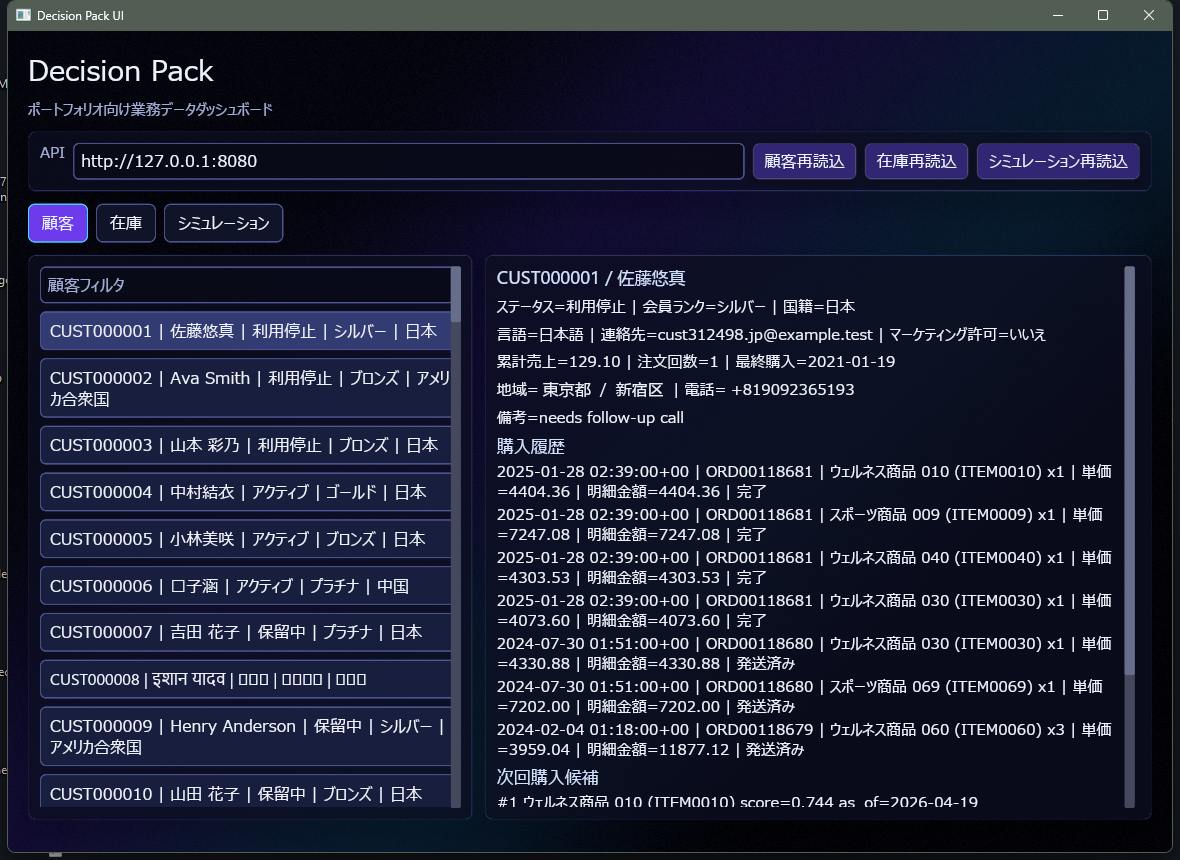
顧客画面では、顧客一覧、会員ランク、地域、購入履歴、次回購入候補を確認します。次回購入候補では、「この顧客が次に買う可能性が高そうな商品」が画面に表示されます。
この画面では、1人の顧客に対する細かな履歴だけが見たいわけではありません。どの地域や会員ランクで購入が多いのか、どの商品が継続して買われているのか、といった次の提案につながる材料があるかという確認も行いたいです。顧客情報と購入履歴を別々に持っているだけでは分かりにくい関係を、画面上で追いやすくしています。
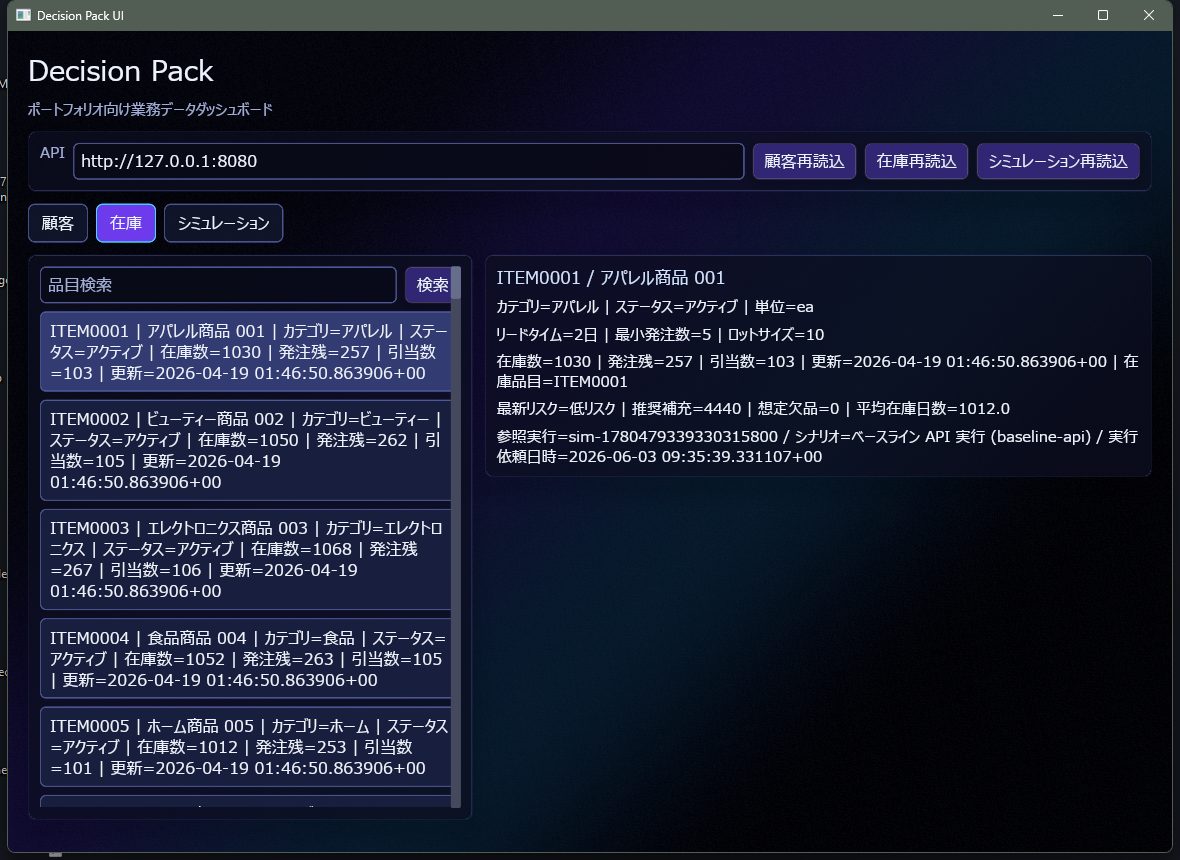
在庫画面では、商品ごとの在庫数、発注残、引当数、在庫リスクを確認します。発注残とは、すでに注文しているが、まだ入荷していない数量のことをいいます。引当数とは、注文や出荷予定に対して、すでに使う予定になっている在庫数のことをいいます。在庫リスクとは、「足りなくなる可能性」や「多く持ちすぎている可能性」を知らせる注意情報のことをいいます。
在庫は、単に数が多ければ多いほど安心というわけではなく、多すぎる在庫は資金を圧迫してしまいます。その一方で、少なすぎる在庫は欠品リスクにつながります。DecisionPack の在庫画面は、単なる現在の在庫数の一覧ではなく、発注、引当、需要、資金への影響リスクを一緒に把握するための画面として考えています。
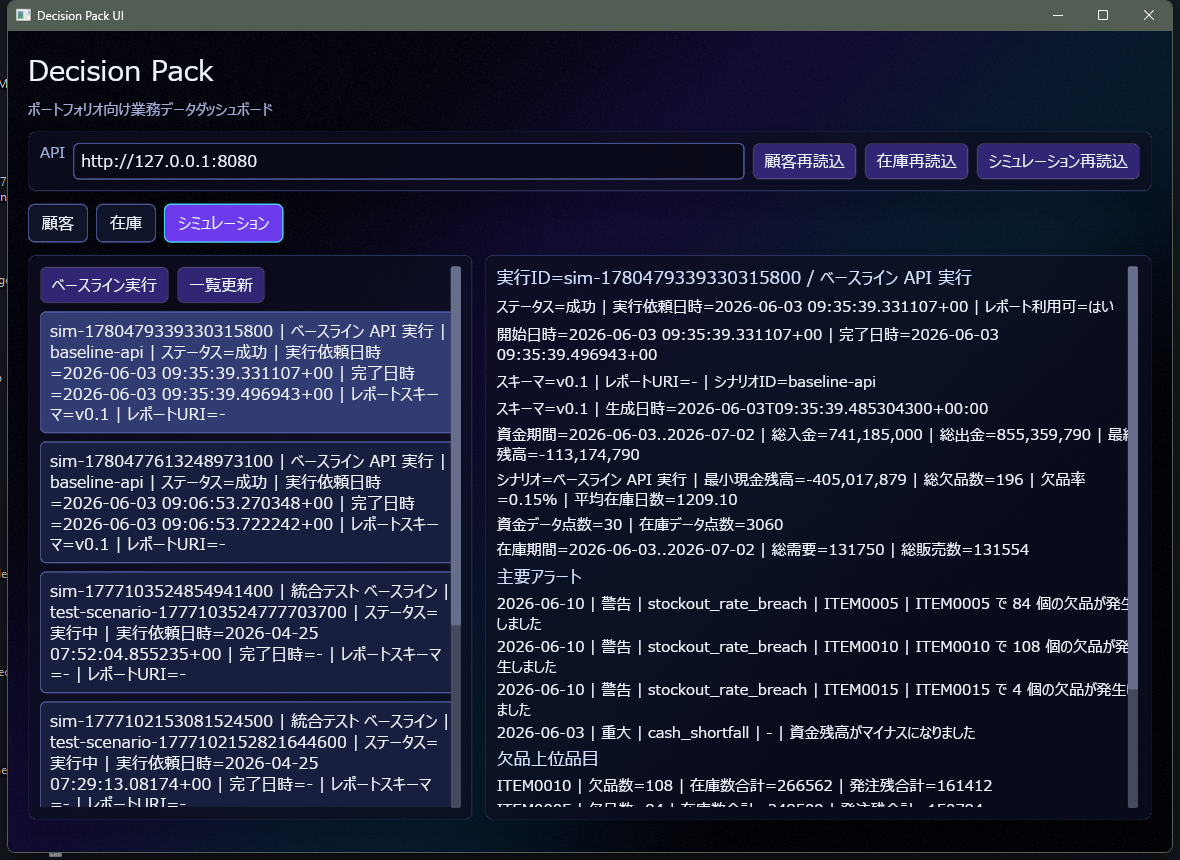
シミュレーション画面では、在庫と需要をもとに、欠品、資金不足、補充候補を試算しています。
この画面では、仕入れ候補を増やした場合に、欠品リスクが減るのか、資金不足が起きやすくなるのかを確認します。現実の業務では、仕入れすぎても少なすぎても良くないため、仕入れに使える資金、在庫を保管する場所、販売までの期間も考慮に入れる必要があります。シミュレーション画面は、そのような複数の条件を見比べて判断するための入口部分に相当します。
技術構成
DecisionPack は、画面だけで完結するアプリではありません。データを前処理する段階、保存する段階、分析処理する段階、判断材料として計算する段階、画面で表示する段階に分かれています。処理を分けることで、どの段階で何が作られたのかを追いやすくしています。
主な技術構成は次のとおりです。
customers-etl: 顧客CSVを整えて保存する処理です。ETL は Extract、Transform、Load の略で、データを取り出し、整えて、保存先へ入れる処理です。commerce-etl: 商品、受注、受注明細、在庫のデータを取り込む処理です。受注明細とは、1つの注文に含まれる商品ごとの内訳です。purchase-insights: 購入傾向と需要予測を作る処理です。decision-engine: 在庫、需要、資金を使って判断材料を計算する中核処理です。engine とは、アプリの中で主要な計算や判断材料作成を担当する部分のことを指します。app-api: 画面と処理本体の受け渡し口です。API は Application Programming Interface の略で、別々の部品が決まった形で情報をやり取りする入口のことをいいます。desktop-ui: 利用者が見る画面です。UI は User Interface の略で、人が操作する画面や表示部分のことをいいます。- PostgreSQL: データベースです。データベースとは、データを整理して保存し、必要なときに取り出せる場所を指します。
処理の流れは、次のように考えると分かりやすいです。
顧客CSV・商品データ・受注データ・在庫データ
↓
ETLで列名・形式・欠損を整理する
↓
PostgreSQLへ保存する
↓
購入傾向と需要予測を作る
↓
在庫数・発注残・引当数を組み合わせる
↓
欠品リスクと資金影響を計算する
↓
APIで画面用データへ変換する
↓
顧客・在庫・シミュレーション画面で確認するこのフローチャートにおいて、入力データをいきなり画面に出さないことが特に重要です。顧客CSVや在庫データは、列名や表記がそろっていない場合があります。たとえば、同じ意味でも「顧客ID」「customer_id」「会員番号」のように名前が分かれることがあります。そのため、まず ETL でデータの形式を整え、保存してから分析や画面表示に使用します。
また、購入傾向と在庫判断は、同じ処理の中に押し込まないようにしています。購入傾向は「何が売れやすいか」を見る処理です。在庫判断は「今の在庫や発注状況で足りるか」を見る処理です。似ているように見えますが、それぞれ見る対象が異なるため、別の役割として分けるべきだと考えます。
設計上の決定事項
1つ目は、画面に重い処理を持たせないことです。画面は見るだけの場所、APIは受け渡し口、エンジンは計算する場所として分離します。これにより、あとから画面の見た目を変えても、中核処理を壊しにくくします。
2つ目は、顧客データと意思決定計算を混ぜすぎないことです。顧客ごとの情報は分析側で扱い、decision-engine には商品単位に集約した情報を渡します。集約とは、細かいデータを目的に合わせてまとめることです。たとえば、個別の購入履歴をそのまま判断エンジンへ渡すのではなく、商品ごとの需要候補として整理して渡します。
3つ目の決定は、文書を正本にすることです。正本とは、判断の基準になる正式な文書のことです。仕様、設計、ADR、運用手順を docs/ に残し、実装がそれに沿うようにしています。逆が基準にならないように念入りに設計等を行います。ADR は Architecture Decision Record の略で、なぜその設計にしたかを残す記録であり、重要な決定ではこれを残すようにしました。
4つ目の決定は、将来の移行を意識した構成にすることです。今はローカル実行を中心にしていますが、Docker Compose や Kubernetes staging へ段階的に進められるようにしています。Docker Compose とは、大まかに複数のアプリ部品をまとめて起動する仕組みであり、Kubernetes staging とは、本番前の確認環境を、複数の部品を管理する仕組みで動かすことです。
5つ目の決定は、判断結果だけでなく、判断材料を残すことを重視するということです。欠品リスクや補充候補だけを出すと、なぜその結果になったのかが分かりにくくなります。そのため、在庫数、発注残、引当数、需要予測、資金影響を見られる形にして、利用者が結果の背景を確認できるようにしています。
現時点の位置づけ
現時点では、PostgreSQL、migration、ETL、購入傾向分析、API、デスクトップ画面、reporting を確認できる状態です。migration とは、データベースの構造を順番に更新する手順です。reporting とは、結果を表や文章にまとめる処理です。
これは本番導入済みの業務システムではありません。業務データを整理し、画面で判断材料を確認できる形にするための設計・実装ポートフォリオです。
公開用画面では、実在する顧客情報や取引情報を全く載せておらず、架空データやサンプルデータを前提にしています。あくまで仕組みと設計判断が分かることを重視したものになります。
Github
ソースコードは GitHub で公開しています。GitHub は、ソースコードや開発履歴を公開・管理できるサービスです。