LaborLensとは
LaborLens は、勤怠CSV、従業員マスタ、人件費、売上、シフト、必要人数、休暇情報を取り込み、労務確認を支援するポートフォリオです。
このポートフォリオは、人事・労務担当者や店舗管理者が、給与計算前の不備、人員不足、長時間労働候補、有給休暇の確認候補を見つけやすくすることを目的としています。
LaborLens は判断代替ではなく確認支援を目指すものです。つまり、法律上の最終判断、人事評価、医療判断を自動で決めるものではありません。システムが結論を出さず、人が確認しやすいように材料を整えることを重視しています。
画面構成
掲載している画面は、人手不足チェック画面です。
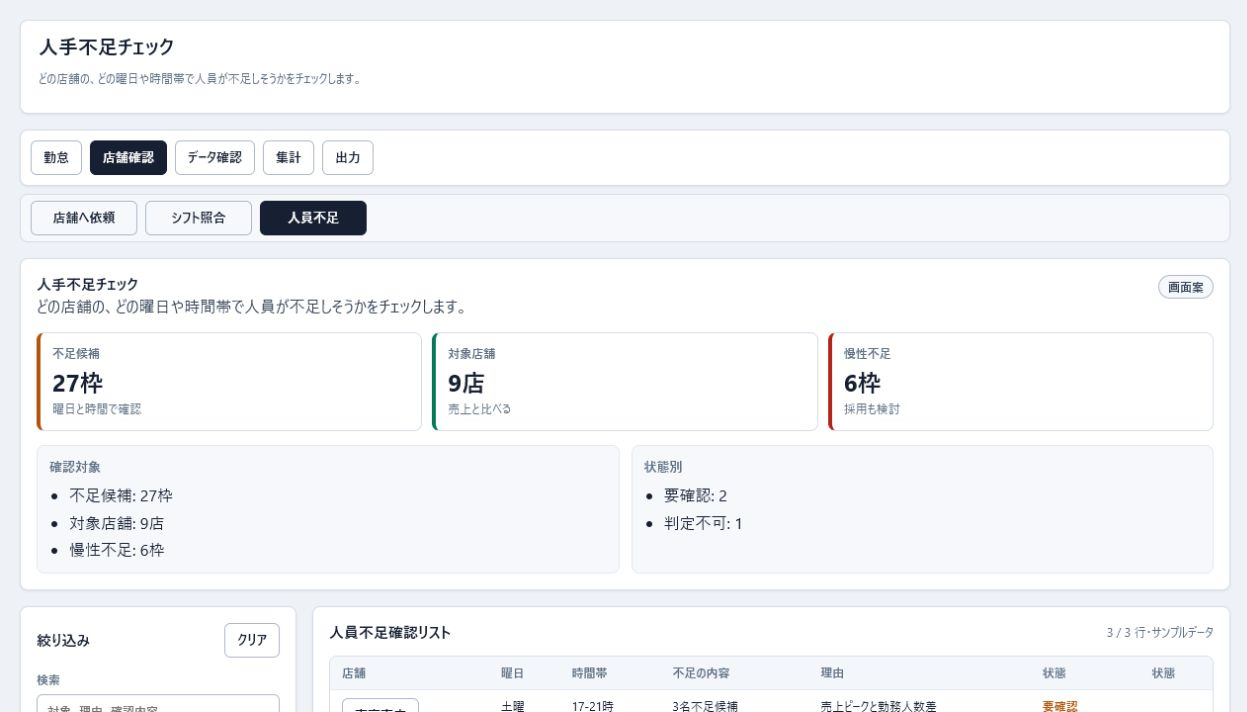
この画面では、不足候補、対象店舗、慢性不足を分けて表示します。不足候補とは、「この曜日や時間帯で人が足りないかもしれない枠」のことです。慢性不足では、一時的な欠員ではなく、何度も不足しやすい状態になっています。
上部の数値カードでは、確認すべき数値をすぐに把握できます。たとえば、不足候補が多い場合は、どの曜日や時間帯に集中しているかを見る必要があります。対象店舗が複数ある場合は、店舗ごとの売上や来客傾向と比べる必要があります。慢性不足がある場合は、短期的な応援だけでなく、採用や配置見直しも検討材料になります。
中段の確認対象では、何を優先して見るべきかを整理します。下段の一覧では、店舗、曜日、時間帯、不足の内容、理由、状態を確認します。一覧は、担当者が「どこから見ればよいか」を判断するための作業リストとして使う想定です。
この画面は、誰かを評価するためのものではありません。人員配置、シフト、売上、必要人数を比べて、仕事が回りにくい場所を見つけるための画面です。
技術構成
LaborLens は、ローカル実行を基本にしています。そのため、自分のPCや社内端末の中で動かすことを想定しています。外部のWebサービスへデータを送る構成ではなく、手元の環境で確認できます。
主な技術構成は次のとおりです。
- React: 画面を作るための JavaScript ライブラリです。
- Tauri: Web技術で作った画面をデスクトップアプリとして配布しやすくする仕組みです。
- Rust: 安全性と速度を重視したプログラミング言語です。LaborLens では、CSV取込、確認候補の整理、レポート生成などの処理を行うために使います。
- Local Server API: 画面と処理本体の受け渡し口です。API は Application Programming Interface の略で、別々の部品が決まった形で情報をやり取りする入口です。
- PostgreSQL: データベースです。データベースとは、データを整理して保存し、必要なときに取り出せる場所です。
- Guide AI: 操作方法やレポートの読み方を説明する補助AIです。
LaborLens では、画面がすべての処理を直接持つ構成にはしていません。画面は表示と操作を担当し、Local Server API が処理本体との受け渡しを行います。Rust 側は、CSVの読み込み、データの検査、確認候補の作成、レポートの生成を担当します。
以下は、勤怠や売上データを画面に出すまでのフローチャートです。
勤怠CSV・売上データ・必要人数データ
↓
原本を保護して記録する
↓
列名・形式・単位をそろえる
↓
勤怠不備や人員不足候補を見つける
↓
個人情報や少人数データを抑制する
↓
抑制後の結果をレポートや画面用データにする
↓
担当者が画面で確認する見せると危険な情報を抑制により表示しないようにしています。たとえば、個人の疲労値や睡眠時間をそのまま画面に出さない設計にしています。少人数データとは、人数が少なすぎて個人が推測されやすい集計のことです。
設計上の決定事項
1つ目の決定は、原本CSVを変更しないことです。原本CSVとは、利用者が最初に入れた未加工のファイルです。元データを勝手に書き換えず、別のデータとして整理します。これにより、あとから「元のファイルではどうなっていたか」を確認しやすくなります。
2つ目の決定は、issue と business check を分けることです。issue とは、欠損、形式エラー、列の不一致など、データ上の確認が必要な状態です。business check とは、データエラーではないが、業務上見た方がよい確認候補です。たとえば、打刻漏れは issue に近く、特定の時間帯で人員不足が続くことは business check に近いです。
3つ目の決定は、抑制前データを通常画面や Guide AI に出さないことです。抑制前データとは、個人情報や少人数集計など、公開前に注意が必要な情報を含むデータです。通常画面には、抑制後の情報だけを出す方針にしています。これにより、便利さと安全性のバランスを取りやすくなります。
4つ目の決定は、すべての処理に RunId を持たせることです。RunId とは、1回の取込、検査、成果物生成を追跡するための番号です。あとから「どの入力から、どの結果が出たか」を追いやすくします。労務データは確認の根拠が重要なので、結果だけでなく、どの処理から出た結果なのかを追えることが大切です。
5つ目の決定は、Guide AI を直接データベースにつながないことです。Guide AI は、操作方法、レポートの読み方、issue の意味、制約条件を説明する補助役です。個人情報を自由に検索する役割ではありません。そのため、Guide AI が参照できる情報は、承認済みで、抑制後の文書や成果物に限定します。
現時点の位置づけ
現時点では、Rust のローカルサーバー、React / Tauri 前提の画面、PostgreSQL 向けのデータ保存、1000人規模の架空データによる勤怠レビュー、労務分析 preview、修正前後の再確認、Guide AI の入口を実装しています。preview とは、本格運用前に画面や処理の方向性を確認するための試作表示です。
これは商用提供物や完成済み製品ではありません。実務利用に近い労務分析アプリを、プライバシーと安全境界を意識しながら設計・実装するポートフォリオです。
また、掲載しているデータは架空データです。実在する従業員や企業は全く含まれず、確認用のサンプルデータのみになります。公開用の画面や説明では、実在する個人情報を使わない方針にしています。
Github
ソースコードは GitHub で公開しています。GitHub は、ソースコードや開発履歴を公開・管理できるサービスです。